6. データを編集・加工する
学習目標
- 既存列から新しい列を追加できる(計算列・定数列)
- 条件を満たす行だけを抽出できる(boolean indexing、
query()) apply()で関数を列・行に適用できる- 文字列メソッド(
str.lower(),str.strip(),str.replace()ほか)で列の表記を整えられる
本文
なぜ「編集・加工」が必要か
CSV を読み込んだ直後のデータが、そのまま集計や可視化に使える形になっていることはほとんどありません。実際の作業の流れはこんな具合です:
- CSV を読み込む(前単元)
- 「分析したい列」を作る:例として「年齢」から「年代」を作る、「身長」と「体重」から「BMI」を計算する
- 「不要な行」を落とす:欠損だらけの行、テスト用ダミー、対象外の地域
- 「表記を整える」:「東京」「東京都」「TOKYO」を一つに揃える
- 集計・可視化(次単元以降)
この 2〜4 のステップ が「編集・加工」です。公開データの多くは「人が見るために整えられた表」であり、そのままだとプログラム処理に向かない形になっています。
たとえば下図のようなオープンデータでは、上の方の数行はタイトル・出典・空行が並び、右端には不要な集計列があります。これをそのまま read_csv で読むと、列名が「Unnamed: 1」のようになり扱えません。
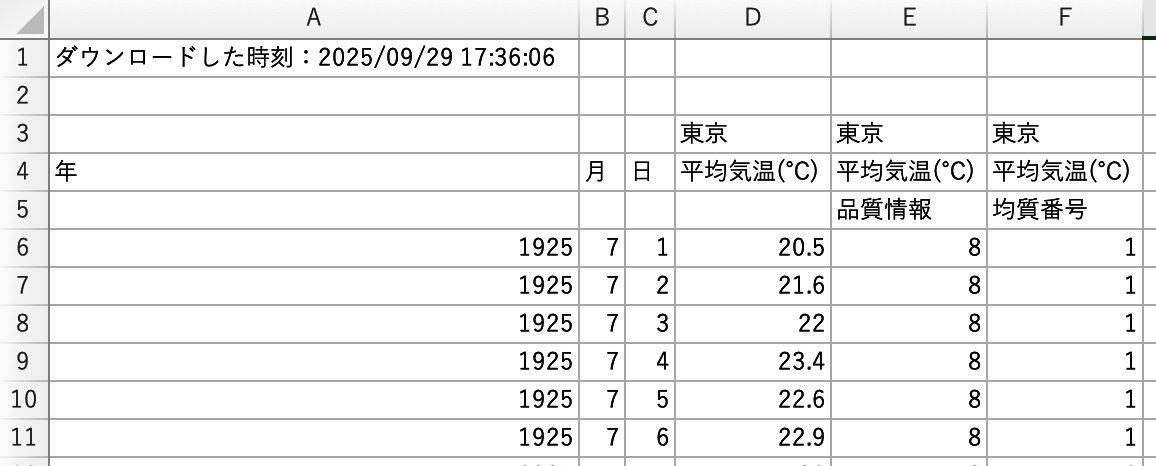
こうした「汚れ」を本単元の道具で整えていきます。
新しい列を追加する
既存の列から計算して新しい列を作るのは pandas の基本動作です:
df["age_next"] = df["年齢"] + 1
df["bmi"] = df["体重"] / (df["身長"] / 100) ** 2代入の左辺に存在しない列名を書くと、その列が新規に作られます。既存の列名を指定すれば上書きです。
定数を入れたいときも同様:
df["国"] = "日本" # 全行に "日本"条件で行を抽出する
「年齢が 30 以上の行だけ」を取り出したいとき、pandas では boolean indexing を使います:
df[df["年齢"] >= 30]df["年齢"] >= 30 は True/False の Series を返し、それを df[...] の ... に渡すと、True の行だけが残ります。
複数条件は &(AND)と |(OR)でつなぎます。各条件はカッコで囲むのが鉄則:
df[(df["年齢"] >= 30) & (df["都市"] == "東京")]Python の and / or は使えない点に注意。Series 同士の論理演算は & / | を使います。
query() を使うと SQL に近い書き方ができ、複雑な条件では読みやすくなります:
df.query("年齢 >= 30 and 都市 == '東京'")どちらでも構いません。短い条件なら boolean indexing、長い条件なら query()、と使い分けるとよいでしょう。
apply() で関数を当てる
単純な列演算では足りない加工は apply() を使います。列(Series)に関数を当てる例:
def 年齢区分(age):
if age < 20:
return "未成年"
elif age < 65:
return "現役世代"
else:
return "高齢者"
df["区分"] = df["年齢"].apply(年齢区分)ラムダ式で短く書くこともできます:
df["age_next"] = df["年齢"].apply(lambda x: x + 1)ただし、上の例は df["age_next"] = df["年齢"] + 1 のほうがずっと速く読みやすいです。apply は「ベクトル演算で書けない処理」のときに使う のが原則です。
文字列メソッドで表記揺れを直す
文字列の列に対しては、.str アクセサ経由でさまざまなメソッドが使えます:
df["都市"] = df["都市"].str.strip() # 前後の空白を削除
df["都市"] = df["都市"].str.replace("都", "") # 「東京都」→「東京」
df["都市"] = df["都市"].str.upper() # 大文字に揃える複数の表記揺れを一気に直したい場合は replace を辞書で使うのが便利:
df["都市"] = df["都市"].replace({
"東京都": "東京",
"TOKYO": "東京",
"とうきょう": "東京",
}).str.replace() は 文字列の置換(部分一致)、.replace() は 値の置換(完全一致)と覚えると区別しやすいです。
よく出る躓きどころ
df["列"]への代入は 元の DataFrame を変える —df2 = df[df["年齢"] >= 30]; df2["新列"] = ...の流れでSettingWithCopyWarningが出ることがある。対処はdf2 = df[...].copy()で明示的にコピーを作るand/orを使ってしまう — Series 同士の論理演算は&/|、各条件はカッコで囲むapplyを多用して遅くなる — ベクトル演算で書ける処理はapplyを避ける(大規模データでは桁違いに速度差が出る).str.replace()と.replace()の混同 — 部分一致か完全一致か、目的に応じて使い分ける
サンプルコード
- 題材データ:users.csv をダウンロード(名前・年齢・都市・性別・カテゴリ・備考の 6 列)
演習
users.csv を題材に、次の加工を順に行いなさい。
- 新しい列
年代を作成し、年齢を「20代」「30代」「40代」のように 10 歳刻みの区分に変換する(ヒント:applyまたは(年齢 // 10) * 10を文字列化) 都市列に対して.str.replace("都", "")を当てて、「東京都」のような表記を「東京」に揃える- 「備考」列が「あり」の行だけを抽出して新しい DataFrame
df_with_noteを作る df_with_noteを CSV として書き出す(index=False)
3 番では df[df["備考"] == "あり"].copy() のように .copy() を付けると、その後の変更で警告が出にくくなります。
発展課題(オプション)
query()を使って複数条件の抽出(例:「東京かつ年齢が 30 以上」)を 1 行で書いてみる- 文字列カラムに対して
str.contains("東")を使い、「東」を含む都市だけを抽出する applyでカスタム関数を作り、独自の区分(たとえば BMI から「やせ/標準/肥満」)を返してみる