4. Pandas と DataFrame 入門
学習目標
- pandas をインポートし、
SeriesとDataFrameを生成できる shape/columns/dtypes/info()/describe()で DataFrame の全体像を把握できるdf["列名"]で列を、df.iloc[i]/df.loc[label]で行を、df.loc[行, 列]でセルを取り出せる- Series と DataFrame の違いを 1 行で説明できる
本文
Pandas を使う理由
Python だけでも CSV ファイルを 1 行ずつ読み込んで処理することはできます。ただし「表形式のデータ」を扱うとなると、行と列の構造を自分で管理しないといけないので、すぐに煩雑になります。
pandas は「表をオブジェクトとして扱う」ためのライブラリで、Python のデータ分析の事実上の標準になっています。CSV を 1 行で読み込み、列を指定して集計し、結果を CSV に書き戻す、という一連の操作がすべてこのライブラリ内で完結します。本コースで扱う集計・前処理・可視化はすべて pandas を中心に進めます。
インポート
Colab には pandas が最初からインストールされているので、import するだけで使えます。
import pandas as pdpd という短い別名を付けるのが慣例で、世界中のサンプルコードがこの書き方をしています。本コースでも以後 pd で統一します。
Series — 1 列ぶんの「ラベル付き配列」
pandas の最も基本的なデータ構造が Series(シリーズ) です。Python の標準のリストに似ていますが、各要素に インデックス(ラベル) がついている点が違います。
s = pd.Series([10, 20, 30], index=["a", "b", "c"])
s実行すると次のように表示されます:
a 10
b 20
c 30
dtype: int64左側の a, b, c がインデックス、右側の 10, 20, 30 が値です。値を取り出すときはラベルでアクセスできます:
s["a"] # → 10整数の位置でもアクセスできますが(s[0])、ラベルを付けられるのが Series の利点です。後で DataFrame を扱うとき、この「ラベル」が列名として活きてきます。
DataFrame — 表の構造
実際の業務や研究では 1 列だけのデータより、Excel のシートのような 表 を扱う場面の方が圧倒的に多くなります。表は DataFrame(データフレーム) として扱います。
DataFrame は 行(row)と列(column)から構成される 2 次元の表形式 で、各行には 0 から始まるインデックス番号が自動的に割り当てられ、各列にはカラム名が付いています。
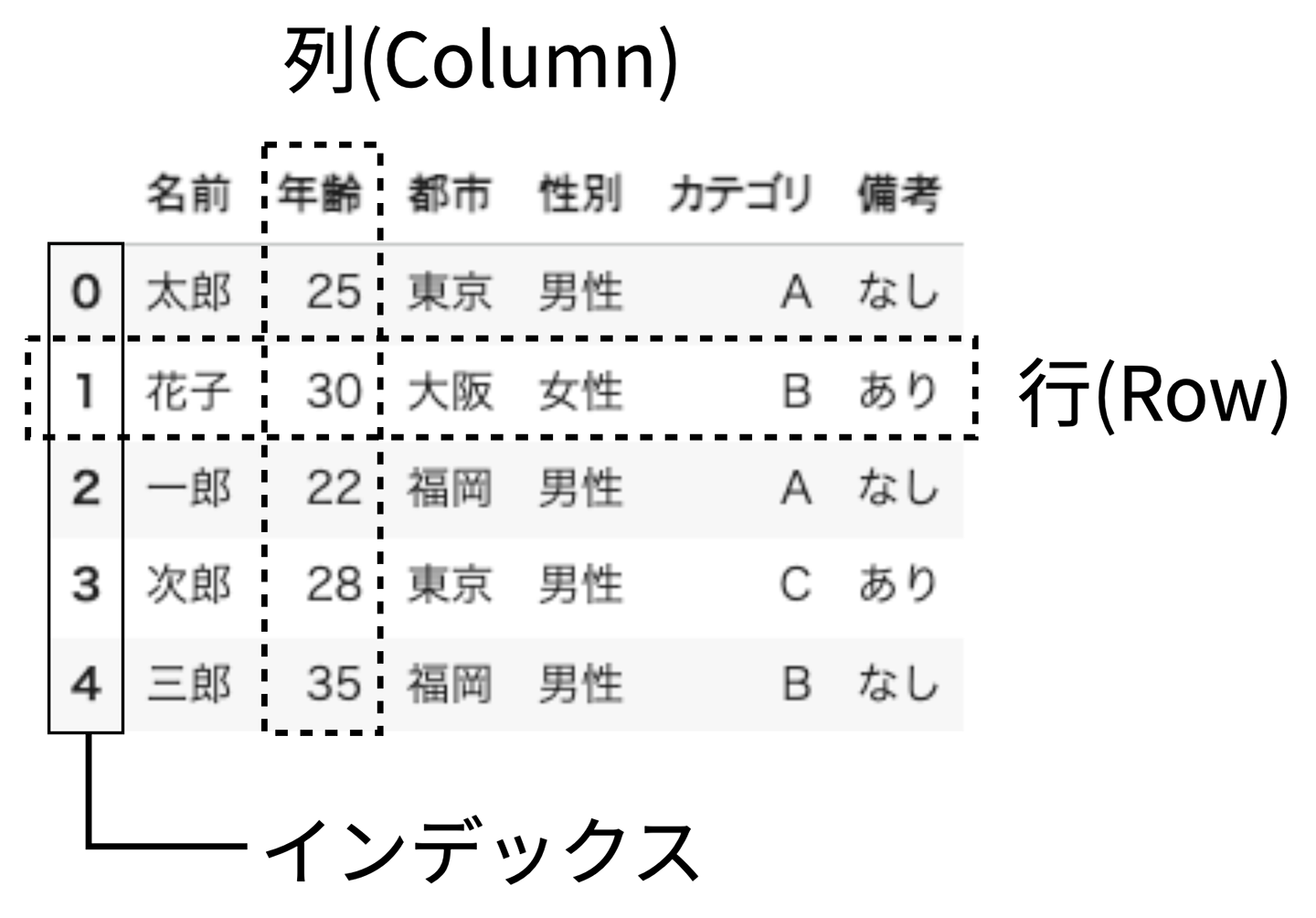
主な構成要素:
- 列(Column) — 縦方向のデータのまとまり。各列には名前(カラム名)が付いている
- 行(Row) — 横方向のデータのまとまり。各行に 1 つのデータレコードが含まれる
- インデックス(Index) — 各行を識別するための重複しない値(通常は 0 から始まる連番)
DataFrame を作る
DataFrame は「複数の Series が縦に並んだもの」と考えると分かりやすいです。次は辞書から DataFrame を作る例:
df = pd.DataFrame({
"name": ["太郎", "花子", "一郎"],
"age": [25, 30, 22],
"city": ["東京", "大阪", "福岡"],
})
df出力:
name age city
0 太郎 25 東京
1 花子 30 大阪
2 一郎 22 福岡辞書のキー(name, age, city)が 列名 になり、リストの中身が各列の値として並びます。左端の 0, 1, 2 は 行のインデックス(デフォルトでは整数の連番)。
実データは普通、CSV から読み込みます(前単元):
df = pd.read_csv("/content/drive/MyDrive/datasets/users.csv")
df.head()df.head() は先頭 5 行を表示する関数。読み込んだ直後にまず眺めて、データの形と中身をイメージするのが定石です。
全体像をつかむ 6 つの操作
新しいデータを開いたら、いきなり中身を加工する前に まず全体像を眺める のが定石です。次の 6 つを順番に呼ぶだけで、データの規模・列構成・型・分布の感触がつかめます。
| メソッド/属性 | 内容 |
|---|---|
df.shape | (行数, 列数) のタプル |
df.columns | 列名の一覧 |
df.dtypes | 各列のデータ型(数値か文字列か) |
df.info() | 列数・行数・型・欠損数をまとめて表示 |
df.head() | 先頭 5 行(引数で件数指定可:df.head(10)) |
df.describe() | 数値列の要約統計(平均・標準偏差・最小・最大ほか) |
実行例:
print(df.shape) # (6, 6)
print(df.columns) # Index(['名前', '年齢', '都市', '性別', 'カテゴリ', '備考'], dtype='object')
print(df.dtypes)
df.info()
df.head()
df.describe()ここで気を付けたいのが、属性とメソッドの区別 です。shape・columns・dtypes は属性なので () を付けず、head()・info()・describe() はメソッドなので () を付けて呼びます。最初は紛らわしいですが、エラーメッセージで「shape() takes 0 positional arguments...」のような表示が出たら属性とメソッドを間違えている合図です。
df.info() の読み方
df.info() を呼ぶと、次のような表が出ます:
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 6 entries, 0 to 5
Data columns (total 6 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 名前 6 non-null object
1 年齢 6 non-null int64
2 都市 6 non-null object
3 性別 6 non-null object
4 カテゴリ 6 non-null object
5 備考 6 non-null object
dtypes: int64(1), object(5)
memory usage: 420.0+ bytes主な読み方:
RangeIndex: 6 entries, 0 to 5— 行数は 6、インデックスは 0 から 5 までData columns (total 6 columns)— 列数は 6Non-Null Count— 各列の 欠損ではない値の数。たとえば「年齢」列が5 non-nullなら、6 行中 1 行が欠損Dtype— データ型。int64は整数、objectは文字列などdtypes: int64(1), object(5)— 全列の型の内訳
「欠損があるか」「数値列はどれか」を一目で確認できるため、データを開いた直後に必ず呼ぶ習慣を付けたい関数です。
df.describe() の読み方
df.describe() は 数値列 に対して、代表的な要約統計を一覧で返します:
年齢
count 6.000000
mean 30.000000
std 6.603030
min 22.000000
25% 25.750000
50% 29.000000
75% 33.750000
max 40.000000| 出力 | 意味 |
|---|---|
count | 有効なデータの個数(欠損を除く) |
mean | 平均値 |
std | 標準偏差(ばらつきの指標) |
min | 最小値 |
25% | 第 1 四分位数(下から 25% の位置) |
50% | 中央値(50% の位置) |
75% | 第 3 四分位数(下から 75% の位置) |
max | 最大値 |
文字列の列は集計対象から外れ、数値列だけが表示されます。
列にアクセスする
特定の列だけを取り出す書き方は 2 つあります:
df["name"] # 1 列だけ → Series が返る
df[["name", "age"]] # 複数列 → DataFrame が返る(リストで囲む)df["name"] と df[["name"]] は 見た目が似ているが戻り値の型が違う 点に注意してください。前者は Series(1 列分のラベル付き配列)、後者は DataFrame(1 列だけの表)です。可視化など「DataFrame を渡したい」場面では後者を使い分けます。
行にアクセスする
行を取り出すには 2 つの基本方法があります:
df.iloc[0] # 位置で取り出す:先頭行
df.iloc[-1] # 末尾行
df.iloc[0:2] # スライス:0 行目と 1 行目(2 行目は含まない)
df.loc[0] # ラベルで取り出す:インデックスラベルが 0 の行ilocは integer location(位置) で指定locは label(ラベル) で指定
デフォルトのインデックスは整数の連番(0, 1, 2, ...)なので両者は似た見た目になりますが、インデックスを別の値(たとえば学籍番号や日付)に振り直すと挙動が分かれます。最初のうちは「数字で当てるなら iloc、名前で当てるなら loc」と覚えておけば十分です。
セル(特定の値)にアクセスする
1 つのセルだけを取り出すなら:
df.loc[0, "age"] # 行ラベル 0、列名 "age" の値 → 25
df.at[0, "age"] # 単一セルの高速版普段は loc で十分ですが、ループ内で何千回も単一セルにアクセスする場面では at の方が体感で速くなります。
値の出現回数を調べる
カテゴリ列で「どの値が何個あるか」を知りたいときは value_counts() が便利です:
df["都市"].value_counts()結果:
都市
東京 2
大阪 2
福岡 2多い順に並べた表が返るため、「どんなカテゴリが含まれていて、それぞれがどれくらいの規模か」をすぐ把握できます。前処理を始める前に呼んでおくと、表記揺れ(「東京」と「東京都」の混在)も発見しやすくなります。
よく出る躓きどころ
df["name"]とdf[["name"]]— 戻り値の型(Series か DataFrame か)が違う。可視化メソッドに渡すと挙動が変わるdf.iloc[0]とdf.loc[0]— デフォルトでは見た目が同じだが、インデックスを振り直すと別物になるdf.head()とdf.head—()を付け忘れると関数オブジェクトを返すだけで実行されない- 属性とメソッドの混同 —
df.shapeには()を付けず、df.info()には付ける。エラーメッセージで「takes 0 positional arguments...」が出たら間違いのサイン
サンプルコード
- 題材データ:users.csv をダウンロード(名前・年齢・都市・性別・カテゴリ・備考の 6 列)
Drive にアップロードした users.csv を Colab で開く例:
from google.colab import drive
drive.mount('/content/drive')
import pandas as pd
df = pd.read_csv("/content/drive/MyDrive/datasets/users.csv")
print(df.shape)
print(df.columns.tolist())
df.dtypes演習
users.csv を Colab に読み込み、次の操作を順番に試してください。
df.shape/df.columns/df.dtypesを表示するdf.info()とdf.describe()を呼んで、欠損数・型・年齢の要約統計を確認する- 「年齢」列だけを Series として取り出して表示する
- 「名前」と「都市」の 2 列だけを DataFrame として表示する
iloc[0]で先頭行を取り出して表示するdf.loc[0, "年齢"]で「太郎の年齢」を単一値として取り出すdf["都市"].value_counts()で都市の出現回数を確認する
各操作の出力を見て、戻り値の型(Series か DataFrame か単一値か)を意識しながら進めると、本文の説明と結びつきやすくなります。
発展課題(オプション)
- 辞書から自分で 5 行 4 列の DataFrame を作成し、
head()/tail()/describe()を呼んでみる df["年齢"] + 1のように Series 全体に演算をかけて、新しい列年齢_翌年を作成するdf.sort_values("年齢")で年齢順に並べ替えて表示する(次回以降の単元で詳しく扱います)